Tobin SouthらによるAuthenticated Delegation and Authorized AI Agentsという論文の邦訳を載せておきます。
日本語でかかれた解説(要約?)の記事もあるので、そのほうが素早く理解できるかもしれません:【論文翻訳】認証された委任と認可されたAIエージェント
翻訳
Abstract
自律型AIエージェントの急速な導入により、デジタル空間における認可、説明責任、アクセス制御に関する喫緊の課題が生じています。AIエージェントが誰に代わって行動するかを把握し、その使用を適切にガイドし、オンライン空間を保護しながら自律型エージェントへのタスク委任の価値を解き放つための新しい標準が必要です。我々は、AIエージェントへの認証済み、認可済み、監査可能な権限委任のための新しいフレームワークを紹介し、これは人間のユーザーが明確な説明責任の連鎖を維持しながら、エージェントの権限とスコープを安全に委任および制限することになります。このフレームワークは、既存の識別およびアクセス管理プロトコルに基づいており、OAuth 2.0とOpenID Connectをエージェント特有の資格情報とメタデータで拡張し、既に確立されている認証およびウェブインフラストラクチャとの互換性を維持します。さらに、柔軟な自然言語の権限を監査可能なアクセス制御構成に変換するためのフレームワークを提案し、多様なインタラクションモダリティにおよびAIエージェント機能の堅牢なスコープ設定を可能にします。これらを総合すると、この実用的なアプローチにより、主要なセキュリティと説明責任の懸念に対処しながらAIエージェントを迅速に導入することが可能になり、エージェントAIシステムが適切なアクションのみを実行することを保証し、スケーラブルなインタラクションによる損害のリスクなしにAIエージェントのインタラクションを可能にするツールをデジタルサービスプロバイダに提供できるようになります。
Machine Learning, ICML
1. Introduction
エージェント型AIシステムは、AIアシスタントまたは単に「エージェント」とも呼ばれ、ユーザーに代わって限定的な直接監督の下で複雑な目標を達成できるAIシステムであり(Gabriel et al., 2024; Chan et al., 2024a; Shavit et al., 2023; Chan et al., 2023; Kenton et al., 2023)、様々な外部デジタルツールやサービスとのインタラクションを含みます(Nakano et al., 2021; Lieberman, 1997; Fourney et al., 2024)。例えば、休日の旅行手配を予約するように指示されたAIエージェントは、ウェブを閲覧しておすすめを探したり、APIを介してフライトを検索したり、チャットサービスを介して自然言語で航空会社のエージェントにメッセージを送信して予約を手配したりできます。このようなコミュニケーションは、AIエージェントの交渉(Abdelnabi et al., 2023)およびその他のマルチエージェントコンテキストにまで及ぶ可能性があります。
現在のAIエージェントには限界があり(Raji et al., 2022; Wang et al., 2023)、特定のタスクを実行する能力が欠如しており(Liu et al., 2023a)、プロンプトインジェクションなどの攻撃を受けやすい可能性があるものの(Yao et al., 2024; Liu et al., 2023b; Zhu et al., 2023)、その開発と商業的関心は急速に高まっています。
このことにより、AIエージェントのリスクとその管理方法について多くの懸念が生じています(Shavit et al., 2023; Gabriel et al., 2024; European Commission, 2021)。資格情報と検証は、AIシステムのプロパティとメタデータを検証する上で必要不可欠になる可能性があり(Chan et al., 2024a)、オンライン空間で人間を一意に識別し(Borge et al., 2017a)(または少なくとも人間とAIエージェントを区別し(Adler et al., 2024))、コンテキストの信頼性を保護し(Jain et al., 2023)、AI拡張影響操作を軽減し(Goldstein et al., 2023)、AIによる人間の操作を防ぎ(Bai et al., 2023; Singh et al., 2024)、そしてより広い意味でのAIシステムの管理や監査をおこないます(Reuel et al., 2024; South et al., 2023)。この世界には、エージェントに権限を明示的に委任し、それらエージェントをAIとして透過的に識別し、エージェントに対するセキュリティとパーミッションに関する人間中心の選択を強制する方法が必要です。
我々はここで、3つのキーコンセプトを見出しています:認証はエンティティのアイデンティティを確認します;認可は、認証されたアイデンティティが実行することを許容されるアクションとリソースアクセスを決定し、委任されたアクティビティのスコープと制限を定義します;監査可能性は、すべての関係者がクレーム、資格情報、および属性が変更されていないことを検査および検証できるようにし、信頼できる認証と認可の決定をサポートします。
この研究には、3つの重要な貢献があります。第一に、セクション2では、既存の文献を基にしてAIエージェントにとって認証された委任がなぜ重要なのか、またどのようなリスクを軽減できるのかを概説します。その際に、現在の取り組みとその不十分な点について概要を示します。第二に、セクション3では、AIエージェントに対して認証された委任を可能にするために既存の認証と認可のプロトコルを拡張し、実用的で検討かつ拡張可能な実装を実現するうえでOpenID ConnectおよびOAuth 2.0が果たす役割を検討することによってこのニーズに直接的に対処します。第三に、セクション4では、エージェントアクセス制御の役割について探索し、エージェントにとって柔軟な自然言語によるパーミッションを表現し、エージェントモダリティ全体(例えば、Webリクエスト、コンピューターの利用や言語インタフェース)で機能する監査可能できめ細かいアクセス制御ルールに変換するための方法を概説し、さらに、この研究ではAppendix Cにおいてこのフレームワークのユースケース例を提供し、サブセクション5.5においてこの研究の影響の法的な分析を提供します。

2. なぜ認可された委任が重要なのか
認証された委任とは、ツール、Web、またはコンピュータ環境へのアクセスを必要とするタスクを 、第三者が(a)インタラクトするエンティティがAIエージェントであること、(b)AIエージェントが特定の人間のユーザーに代わって動作していること、および(c)AIエージェントに特定のアクションを実行するために必要な権限が付与されていることを検証できるような方法で、AIシステムに実行するように指示するプロセスです。
インタラクトするエンティティのプロパティを検証することは、AIエージェントが人間のユーザーに代わって行動できるコンテキストが存在する場合、特にエージェントが重大なアクションを実行できる場合に重要です。これは、AIシステムがローカルで実行されるか、AIベンダーによって提供されるかに関係なく当てはまり(どちらでも危害が発生する可能性があるため)、さまざまなデジタルコンテキストを通じ、ヘテロジニアス・ケイパビリティのAIモデルで運用できる必要があります。
大まかに言えば、認証された委任には、特定のAIエージェントがユーザに代わってデジタルサービスにアクセス(または別のAIエージェントとインタラクト)するために使用でき、対応するサービスまたはエージェントによってその信頼性が検証されるデジタル認可を人間のユーザーが作成することが含まれます。このような認可には、エージェントインスタンスの一意の識別子、エージェントが実行できる操作に関する権限、およびその他の情報(例えば、エージェントの機能と故障モード、または人間のユーザーに関する情報)などの追加情報を含めることができます。この認可は、認可を付与した人間の委任者のデジタルアイデンティティに一意かつ暗号的にリンクされている必要があります。これは、(アプリケーションアカウントでは一般的である)電子メールアカウントにリンクすること、より堅牢なデジタルアイデンティティにリンクすること、またはドメイン固有の識別子(組織設定内のユーザーアカウントなど)を介することで実現できます。
実際には、カレンダーアプリケーションがユーザーのカレンダーデータにアクセスして今後のイベントを走査することを認可する方式など、現在使用されている既存の認証および認可メカニズムと大幅に異なっている必要はありません。ただし、AIエージェントの自律性と高度な機能により、委任の管理方法にはより注意が必要です。そこで、認証された委任のユースケースを詳しく見ていきます。
2.1 認証された委任の機能
認証された委任により、AIエージェントは人間のユーザーに代わって複雑なタスクを加速させ、ワークフローを自動化し、そしてデジタルサービスとシームレスに連携できるようになります。しかし、このような権限を付与すると、スコープの不整合、リソースの乱用、または明確な説明責任の崩壊などのリスクも付随します。このサブセクションでは、堅牢なアイデンティティ検証、明示的なスコープ設定、および相互認証によって、主要な脆弱性に対策しながら、合理化されたエンタープライズプロセスから安全なマルチエージェント協調に至るまで、実用的なユースケースを実現する方法について説明します。機会と潜在的な落とし穴の両方をハイライトすることで、安全で検証可能な委任メカニズムを採用することが、AIエージェントを責任を持って活用するために不可欠である理由を強調します。
2.1.1 AIエージェントに権限を委任するさいの現在の課題
LLMの機能が向上するにつれて、より自律的で汎用的なものにすることへの関心が高まっています。その重要な側面は、ツールを使用したり外部サービスにアクセスしたりする機能です。エージェントにWebで情報を検索したり、コードを記述して実行したり、画像を生成したりするように依頼するなどの単純なタスクの場合、これは簡単で、追加の認可や個人固有のセキュリティメカニズムは必要ありません。ただし、個人または組織のアカウントとのやり取り、機密性の高い個人情報へのアクセス、または重要なインフラストラクチャとのやり取りなどのユースケースを実現するには、より堅牢な委任フレームワークが必要です。
例: 上記のAIエージェントによる休暇の予約の例について考えてみましょう。エージェントがWebで情報を検索する場合、認可は不要かもしれませんが、そのエージェントがユーザーのカレンダーにアクセスしたり、購入したりするにはどうすればよいでしょうか?カレンダーの場合、ユーザーはカレンダーデータにアクセスするためにアプリケーションにアクセス権を付与するという想定されるフローに慣れています。これはAIエージェントでも違いはありません(セクション3で概説するソリューションで単純にサポートされます)。実際、OpenAI GPTアクションなどの一部のエージェントツールでは、限定的な OAuth 2.0サポートが有効になっています。次に、フライトの購入について考えてみましょう。エージェントのコンテキストウィンドウでクレジットカードの詳細を提供し、予算内で実行するように促すこともできますが、これには様々なセキュリティ上の懸念が生じ、予期しないアクションを実行したり、攻撃やジェイルブレイクに対して脆弱になったりしないというAIシステムの基盤となる信頼性に依存することになります。代わりに、AIエージェントはクレジットカードが安全に保管され、明示的な支出制限を強制できる特定の予約サービスで購入をおこなうために認証および認可をされるべきです。
2.1.2 コミュニケーションの制限とスコープの制限
AIエージェントのスコープを制限する現在のアプローチは限定的で一方的です。ユーザーはエージェントに行動を制限するよう強く促すことができますが、これには様々な故障モードが伴います(Liu et al., 2023b)ツールやウェブサイトへのアクセスをブロックすることはできますが、制御の粒度には限界があります。AIシステムの導入者は、エージェント機能が発生したときに特定のアクションやウェブサイトのサブドメインを監視およびブロックするなどの追加の制御を実装できますが、これらの制限をエージェントがインタラクトしているサービスには伝達しません。AIエージェントのスコープを明示的に制限し、これらの制限をエージェントがインタラクトしているサービスに伝達することで、AIエージェントとサービス間のより堅牢なインタラクトが可能になります。これをWeb、API、自然言語アクセスモダリティ全体でどのように設計できるかについての詳細な検討は、セクション4で確認できます。
例: 遠隔医療ポータルにおいて診断レコメンデーションを提供するため、AIエージェントは医師によって利用され、医師は制限が指定されていない一般的な資格情報によってログインをおこないます。ポータルは医師の資格情報が完全であることを想定し、専門医の音声記録による動画評価を含むすべての患者記録へのアクセスをエージェントに付与します。テキストだけを処理し、動画を処理できないエージェントは、テキストデータだけをもとに診断を生成し、「利用可能なすべての情報を使用したわけではありません」という標準的な警告を付け足しますが、この警告は見落とされます。医師が不完全なレコメンデーションを信頼すると、誤った治療決定をおこなうりすくがあります。認証された委譲によってエージェントの制限が明示的に伝えられていれば、ポータルはマルチメディアコンテンツを人間がレビューする必要があることを警告し、潜在的に害のある見落としを回避できたはずです。
2.1.3 マルチエージェント通信における検証
AIエージェントがタスクの共同作業やインタラクションの促進のために通信をおこなう場合、相互認証を確実に実行することが重要になります。通信チャネルを保護するだけでは不十分です;つまり、エージェントは、自分が代表していると主張するユーザーまたは組織を本当に代表しているかどうかについても確認しなければなりません。相互認証により、エージェントは互いの意図、機能、権限を信頼できるようになり、なりすまし、認可されていないアクション、および潜在的な悪用を防止することができます。この検証は、信頼性が高く、安全で、かつ説明責任のあるマルチエージェントエコシステムを発展させるために不可欠です。
例: 2つのAIエージェント(一方は病院を、もう一方は保険会社を代表しています)が協調して患者の請求を処理します。病院のエージェントが治療の詳細情報を送信し、保険会社のエージェントが補償範囲を確認します。相互認証がない場合、悪意のある第三者のエージェントが病院エージェントになりすまして不正な請求を送信したり、保険会社エージェントが信頼性を懸念して有効な請求を拒否したりする可能性があります。
2.1.4 Protecting human spaces online
AIエージェントが人間の行動(テキストの作成、ペルソナの作成、さらには絶妙な人間同士のやり取りの再現)を模倣することにますます熟達するにつれて、本物の人間だけが真に生活しているデジタル環境を維持することがより難しくなります。この課題により、人間が人間であることを検証することで真正性が保たれ、スケーラブルな操作が抑制される、安全で人間のみのオンライン空間の必要性が高まっています(Adler et al., 2024)。しかし、多くのAIエージェントは、直接関与できない、または関与したくない人間のユーザーにとって便利なプロキシ、アシスタント、または代表者として機能します。認証された委任により、これらの空間にAIエージェントが選択的にアクセスできるようになる一方で、AIエージェントが検証済みの人間のプリンシパルにリンクされていることが保証されます。

例: 最近のオーストラリア政府によるソーシャルメディア禁止令は、政府がユーザーに多くの場合、政府発行の身分証明書や顔スキャンなどの手段が使った年齢の証明を義務付けることでオンライン空間へのアクセスを制限できることを実証しています。これらの措置は未成年者のアクセスを制限することを目的としていますが、AIエージェントがこれらのプラットフォームにアクセスするのを意図せずブロックしてしまう可能性もあります。プラットフォームは全面的な制限の代わりに、認証された委任を利用して、制御された方法でAIエージェントがサービスにアクセスすることを明示的に許可できます。このアプローチにより、AIエージェントは検証済みの人間のユーザーに代わって透過的に行動できるようになります。たとえば、エージェントはユーザーのソーシャルメディアアカウントにアクセスして友人に関する情報を取得したり、Eメールの作成を手伝ったりすることができ、その際、プラットフォーム ポリシーへの準拠を維持し、説明責任を確保します。
2.1.5 コンテキスト整合性をサポートする
コンテキスト整合性は、アクター(情報の流れに関与する人物)、属性(共有される情報)、伝達についての原則(どのような条件下で情報が共有されるか)、社会的コンテキスト(規範を形成しているより広範な文化的、制度的、または状況的環境)を含むコンテキスト固有の規範とプライバシーの遵守に対処します(Ghalebikesabi et al., 2024; Zhan et al., 2022; Fan et al., 2024; Nissenbaum, 2004)。コンテキスト整合性は、AIエージェントがコンテキスト上で適切で透明性があり、社会規範や人間の委任者の期待に沿った方法で行動できる方法について推論するための視点を提供します(Bagdasarian et al., 2024; Ghalebikesabi et al., 2024; Bloom & Emery, 2022)。これには、AIが自律的におこなうことが合理的だと考えられる決定と、どのような条件下で人間による監視や介入が必要になる可能性があるか(例:ヒューマンインザループが必須な場合と、責任をとるのが誰か)ということの調査が含まれます。
例: 認証された委任を持つAIアシスタントには、個別のコンテキスト(例えば、エンタープライズコンテキストアシスタントと個人コンテキストアシスタントなど)に対して異なる資格情報を発行することが可能です。各資格情報には、エージェントの情報、委任元ユーザー、およびコンテキスト固有の権限がエンコードされます。これらのスコープ指定された資格情報を強制することで、サービスはアシスタントがコンテキストの整合性を順守し、作業文書の情報を使用して個人フォームに記入するなどの境界を越えるアクションを拒否することを保証できます。この役割の分離と明示的な権限の共有により、プライバシーを保護し、説明責任を確保し、コンテキスト間の決定に対する人間の監視を保護します。
2.2 背景
認証された委任は、AIの結果の追跡可能性から、AIシステムがアクセスできる空間および実行できるアクションの制限まで、さまざまな課題に対処できます。識別および認証システムの包括的な目的は、セキュアなオンライン環境とサービスへの認証されたアクセスを促進することです。この目的のために、さまざまな既存のプロトコルと標準が開発され、さまざまな状況でこれらの目標を守るために人間のユーザーとAIシステムの両方に合わせて調整されています。
他のAI識別子との比較
オンラインで人間の身元を確認するために 、OAuth 2.0(Hardt, 2012)のような単純な認証からW3CのVerifiable Credentials(Sporny et al., 2024b)、分散型識別子(Sporny et al., 2024a)、および欧州連合デジタルアイデンティティのプライバシー保護デジタルウォレット(Wallet, 2024)のようなより複雑なデジタルアイデンティティフレームワークまで幅広く仕様が存在します。非公開で人間であることを証明するために 、人間のユーザーとボットを区別するシステムが数多く開発されており、その中には自動化されたシビル攻撃に対抗するために設計されたプルーフ・オブ・パーソンフッドシステム(Borge et al., 2017b)、CAPTCHA(Von Ahn et al., 2003)などの単純なチューリングテスト、そしてより堅牢な資格情報(Adler et al., 2024)が含まれます。より一般的には、ユーザーに対する「know-your-cusotmer」の目標と、きめ細かいアクセス権限(アイデンティティおよびアクセス管理、IAM)は、インターネットでは一般的です。
同様に、多くのウェブサイトは、サービス上でボットのアクセスを広く制限 しようとしており、robots.txt の禁止を利用してそうするかもしれません。ボットや認証されていないAIエージェントが広く存在すると、悪用や危害につながる可能性があるため、これは重要ですが、多くの場合、「ユーザーエージェント」レベルでおこなわれます(たとえば、すべての「GPTBot」ユーザーエージェントを禁止する(Longpre et al., 2024))。
AIシステムの出力を追跡し検証するために、透かし技術(Liu et al., 2024; Wang et al., 2021)とコンテンツ来歴測定(C2PA, 2023)は、AI生成コンテンツの起源を決定するための潜在的な解決策として浮上しています。しかし、これらのアプローチは信頼性の課題に直面しており(Saberi et al., 2024)、AIエージェントを使用する際の包括的な説明責任や安全性を確立するには不十分です。現在の検証方法に固有の限界により、コンテンツの作成だけでなく、AIシステムのデプロイメントとインタラクションのより広範な影響を追跡できる、より堅牢なフレームワークの必要性が浮き彫りになっています。
機密性の高いAI機能へのアクセスを管理する ために、研究者はコンピューティングプロバイダー向けの「know-your-customer」スキームを提案している(Egan & Heim, 2023; O’Brien et al., 2023)一方、商用プラットフォームではAPIトークンとアクセス制御を実装しています(OpenAI, 2023)これらの発展は、AIシステムが外部サービスにアクセスする際にその真正性とパーミッションを証明するための堅牢なメカニズムが必要であるという認識が高まっていることを反映しており(Buterin, 2023)、特に重要なインフラストラクチャと意思決定プロセスにさらに統合されるようになるにつれてその傾向があります。
AIエージェントの特定のインスタンスを識別するために 、最近の研究では、上述の識別子と検証アプローチが提案されています(Chan et al., 2024b, a)。これは重要かつ極めて重要な研究であり、これを基にして、既存の認証およびパーミッションプロトコルを利用してAIエージェントの認証された委任に拡張し、AIエージェントが制御された方法でユーザーに代わって行動することを可能にします。次に、これらの識別子と委任メカニズムは、人間のユーザーに対するゲートキーピングをすることだけでなく、監査可能性と説明責任を備えた状態でAIエージェントがユーザーに代わって行動することを可能にする空間を作成することに役立ちます。
モデルコンテキストプロトコルとGPTアクションとの比較
AI中心のプロトコルの一例としては、最近のモデルコンテキストプロトコル(MCP)(Anthropic, 2024)があり、これはAnthropicが提唱するAIシステムと外部ツールまたはデータソース間のセキュアで構造化されたインタラクションを可能にします。MCPは、モデルをリソースに接続するための標準化されたフレームワークを確立し、ライブデータの収集、APIとのインタラクション、およびリアルタイムでのタスク実行などのアプリケーションを促進することで、AI出力のコンテキスト関連性を高めることを目指しています。
非常に便利な標準ではありますが、そのすべてのスコープは認可された委任に限定されており、より広範な認証およびアイデンティティ管理ではなく、システム通信と任意のアクセス制御のみを有効にしています。
同様に、OpenAIのGPT Actionsは、フライトの予約やAPIからのデータの取得などの特定のアクションの実行をGPTモデルに可能にする統合であり、MCPよりも制限されたバージョンであり、その欠点を共有しています。LangChain のAgent Protocol / LangGraph Platformは、このアイデアを拡張して、マルチエージェントの相互運用性を実現します。
エージェントAIシステムのドキュメント、安全性、ガバナンス
AIシステムとそれを作成するデータの文書化は、研究と実践の重要な分野です。初期のフレームワークでは、データシート(Gebru et al., 2021)、モデルカード(Mitchell et al., 2019)、およびデータステートメント(Bender & Friedman, 2018)を含む基礎的なアプローチが確立され、人気のある実装が出現しています(Paullada et al., 2021)。これらのアプローチはどれも価値があることが証明されていますが、偏見(Buolamwini & Gebru, 2018)、プライバシー、および著作権に関する懸念に適切に対処するには課題があります。最近の研究では、AIエージェントの能力と限界を理解するために、AIエージェントの文書化の必要性が強調され(Chan et al., 2024b)、静的なシステム記述を超えて、動的な振る舞いやインタラクションパターンを把握するようになっています。AIシステムがますますエージェント化されるにつれて、その進化している機能、意思決定プロセス、および潜在的なリスクを文書化するための新しいフレームワークが必要です(Bommasani et al., 2022)。
最近の研究では、エージェントのアクションを検証および元に戻すためのランタイム(Patil et al., 2024)と言語モデル間の構造化された通信プロトコル(Marro, 2024)が検討されています。また、研究者達は欺瞞行為をおこなえる可能性のある機能に特化したフロンティアモデルを評価している(Phuong et al., 2024; Fang et al., 2024)一方で、過去のインシデントを追跡すること(Wei & Heim, 2024)およびAIエージェントのインタラクションに対するより広範な安全策を確立すること(Shavit et al., 2023)を提唱する者もいます。AIエージェントのガバナンスは、研究と実践の分野で急速に進化しており(Reuel et al., 2024; Kolt, 2024)、自律システムの責任あるデプロイメントと運用を保証できるフレームワークの開発にますます注目が集まっています。
認証された委任がこれらのソリューションをどのように組み合わせるか
本研究では、既存のアプローチ(AIエージェントIDと資格情報、人間のユーザーに対するプルーフ・オブ・パーソンフッドとアイデンティティ検証、およびコンテンツ来歴と透かし手法)を組み合わせて拡張し、まとまりのあるフレームワークを形成します。このアプローチは、確立されたアイデンティティ管理のプラクティスを継承しながら、AIエージェントに明示的なスコープとメタデータを導入します。この統合により、きめ細かく強制可能なパーミッションセット、より明確な説明責任チェーン、およびより豊富なコンテキストシグナル(モデルの資格情報や制限など)を各委任アクションに付加できるようになり、単純なエージェントIDシステムカードよりも堅牢に検証可能な構造になります。実際には、認証された委任は既存の標準を補完し、AIエージェントのアクションを検証可能な人間のプリンシパルと認識されたAI固有の資格情報に固定することで信頼性を高め、安全で説明責任のあるAIのインタラクションのための統一された基盤を構築します。この目的のために、セクション3では、これらの要素を堅牢に検証可能な方法でパッケージ化するための追加のセキュリティ保証を備えた具体的なフレームワークを紹介します。
3. AIエージェントの識別と認証のためのOpenID Connectの拡張
セクション2の目的をサポートするために、このセクションでは既存のインターネット規模の認証プロトコルに基づいて、ユーザーからAIエージェントに権限を委任するメカニズムを導入する具体的な技術フレームワークを提案し、OpenID ConnectとOAuth 2.0を活用したトークンベースの認証フレームワークについて説明します。我々のアプローチは、これら歴戦のプロトコルを拡張し、既存のインターネットインフラストラクチャとの互換性を維持しながら、AIエージェント認証に固有の課題に対処します。
3.1 OAuth2.0とOpenID-Connect
AIシステム識別のための新しいフレームワークが登場している一方で、既存のインターネット規模の認可および認証プロトコルから学ぶべき貴重な教訓があります。特に、OAuth 2.0プロトコル(Hardt, 2012)とその拡張仕様は、AIエージェントクレデンシャルシステムの開発に役立つ、委任された認可とアイデンティティ検証のためのよく利用されているパターンを提供します。
OAuth 2.0は、RESTfulパラダイム(Fielding, 2000)のなかで、ユーザーがあるサービスが他のサービスに存在するリソースにアクセスする認可を提供する必要性から生じました。OAuth 2.0の根底にある重要な要件は、ユーザーが不在(例えば、オフライン)になった場合でも、継続的にアクセスを許可する機能です。既存のユーザー認証プロトコル(例:MIT Kerberos(Neuman et al., 2005)、CHAP(Simpson, 1996))は、主にUDPレイヤーを介して認証サーバーに接続するホストコンピューターを使用する人間のユーザー間のインタラクションのために開発されました。RESTful APIの登場により、パラメーターとフローはHTTPレイヤーを介して通信する必要があり、TLSが基礎となるメッセージ機密レイヤーを提供するようになりました。
OAuth 2.0が対処する典型的なシナリオ例は、オンラインカレンダーサービスが航空会社のサービスからユーザーの旅程を読み取ることを許可したいユーザーです。ここで、リソースへのアクセスを求めるサービスはOAuth 2.0クライアントと呼ばれます。一方、リソースを管理するサービスはリソースサーバー(RS)と呼ばれます。OAuth 2.0の前提の1つはクライアントとRSがサードパーティのエンティティによって操作される可能性があるという事実に注意することが重要です。
OAuth 2.0プロトコルの幅広い導入と人気により、新しい機能や拡張機能が追加されるようになりました。成功した拡張機能の1つは、OpenID-Connectプロトコル(OIDC)(Sakimura et al., 2014)であり、これはユーザー認証を扱うフローを追加しています。認証を扱うサービスはOpenID プロバイダー(OP)と呼ばれます。OpenID-Connectによって導入された重要な追加機能はIDトークンであり、これはOPから取得できる人間のユーザーに関する情報を保持しています(つまり、IDトークンを提示することによって)。ここで、販売者(リライングパーティーとして)は、ユーザーに関するさらなる情報を取得するために、OP上の関連するトークン検証エンドポイントにIDトークンを入力します。我々は、この機能をAIエージェントのケースに対応するために拡張できると考えています。
OAuth 2.0プロトコルのもう1つの拡張機能は、ユーザーが多数のリソースサーバーに分散された複数のリソースを管理できるようにするユーザー管理アクセス(UMA)プロトコルです(Hardjono et al., 2015)。UMAモデルは、人間のユーザーが複数のAIエージェントを所有し、ポリシーやルールの構成を一元化することが望まれるユースケースに適している可能性があります(Hardjono, 2019)。ここで、AIエージェントは、ユーザーが所有する分散リソースサーバーとして見ることができます。UMA認可サーバーを利用すると、ユーザーは1か所でポリシーを設定し、これらのポリシーを複数のAIエージェントに自動的に伝播させることができます。
3.2 AIエージェントにユーザーから権限を委任する
OAuth 2.0プロトコルは認可プロトコルであるため、OAuth 2.0パターンを再利用し、人間のユーザーが特定のタスクをAIエージェントに委任するための新しいメカニズムを確立することを検討する価値があります。言い換えると、人間のユーザーは、ユーザーに代わってスコープによって限定された特定のタスクを実行することをAIエージェントに認可していることになります。
この新しく提案された拡張機能では、人間のユーザーはまずOpenIDプロバイダー(OP)に対して認証を実行し、自分のアイデンティティを証明する必要があります。次に、ユーザーはAIエージェントをOPに「登録」し、これによって後でAIエージェントに関する詳細情報を取得しようとする外部エンティティがOPに対してその情報を取得できるようになります。登録は、ベンダーを通じてエージェントが作成されたときに(OpenAIで新しいアシスタントインスタンスを作成するなど)、バックグラウンドで自動的に実行できます。
既存のOAuth 2.0クライアント登録プロトコルをカスタマイズして、ユーザーがAIエージェントをOpenIDプロバイダーに登録し、AIエージェントを人間のユーザーの代表または代理人として指定できるようにすることができます。
次に、人間のユーザーは、AIエージェントがユーザーに代わってタスクを実行することを認可する新しい委任トークンを発行できます。ここでは、「認可」という用語は、AIエージェントが人間の委任者によって所有(操作)されているという事実を明示的に示すために使われます。
ユーザーIDトークンとAIエージェント委任トークンは両方とも、W3C Verified Credentials(VC)データ構造内から参照(またはコピー)することができます(Sporny et al., 2022)。これにより、AIエージェントは他のエンティティ(例:他のサービスや他のAIエージェントなど)とのやり取りでVCを活用できるようになり、両方のトークンが標準OPで検証可能になるという利点が得られます。
これらの委任と認証の交換は、W3C VCの発行と委任のメカニズムを使用して実装することもできる点は注目に値します。このようなシナリオでは、W3C VCはOpenID互換のクレデンシャルを生成し、OpenIDシステムとのシームレスなインターフェイスを可能にします。この統合はW3C VCとOpenIDエコシステム間の相互運用性を強調しますが、このプロセスのさらなる調査と形式化は今後の作業として残されており、この論文の範囲外です。

3.3 トークンベース認証フレームワーク
既存のOIDCフレームワークを拡張することで、関連するすべてのAIエージェント属性と委任のメタデータをアイデンティティ関連トークンのセットを提供できます。
- ユーザーのIDトークン:これは、OpenIDプロバイダー(OP)サービスによって発行/署名される既存のID トークンデータ構造です。これは、人間のユーザーに関する情報を表すことを意図しており、日常のログインエクスペリエンスで使用されるものと変わりません。
- エージェントIDトークン:これは、OAuth2.0ネイティブクライアントとして発行されたAIエージェントについての関連情報を伝達し(つまり、AIエージェントの所有者がすべてのキーマテリアルと秘密パラメータを制御します)、対応するサービスがAIエージェントとその情報に関するクレームを検証できるようにします。このトークンには、エージェントの一意の識別子から、システムドキュメント、機能または制限のメタデータ、他のAIシステムとの関係属性、またはその他のシステム特性を含む、より豊富で詳細なエージェントIDトークンまで、さまざまな追加情報を含めることができます。エージェントIDが何を意味するかについてのさらなる議論については、Chanら(2024b)を参照してください。
- 委任トークン:この新しく導入されたトークンは、AIエージェントがユーザーに代わって行動することを明示的に認可します。委任トークンは、人間の委任者によって発行および署名され、対応するユーザーのIDトークンとエージェントのエージェントIDトークン(のハッシュなど)への参照を保持し、OPを信頼する任意のサービスによって検証できるようにします。さらに、委任の性質に関する関連情報を共有できます。たとえば、エージェントの要約された目標とそのスコープ制限を共有することで、第三者がAIエージェントを有用なエンドポイントとインタラクションパラダイムに誘導することに役立ちます。委任トークンは、有効期限や失効エンドポイントなどの有効条件を指定し、偽造を防ぎ、ユーザーがAIエージェントに一覧の権限を意図して付与したことを確認するために、ユーザーによってデジタル署名されている必要があります。さらに、トークンは、ログ記録や監査URLなどの補足メタデータを保持して、サービスプロバイダーがインタラクションを記録し、委任されたアクションを監視し、異常に適切に対応できるようにします。委任トークンが正当なユーザーIDトークンと適切に発行されたエージェントIDトークンを参照していることを検証することで、リモートサービスはアクセスを許可する前にAIエージェントの権限の信頼性とスコープを確認できます。
3.4 委任におけるスコープ制限
委任フレームワークにより、人間のユーザーは委任トークンにスコープ制限をエンコードすることで、AIエージェントのアクションに任意に明確な境界を定義することができます。しかし、エージェントの柔軟な性質と多様なアクション空間を考えると、スコープ設定には独特で興味深い課題があります。
3.5 代替手段として検証可能なクレデンシャルを仕様する
W3C 検証可能なクレデンシャル(VC)標準(Sporny et al., 2022)は、アイデンティティと委任データを伝達するための既存のOpenID Connect(OIDC)フローに多用途の代替手段、場合によっては補完手段を提供します。VCベースのアプローチでは、発行者(組織や個人のような)は、ユーザー、AIエージェント、または検証可能で改ざん防止の属性を必要とするその他のエンティティなど、対象に関するさまざまなクレームを証明するクレデンシャルに署名できます。VCは特定のトランスポートプロトコルにバインドされていないため、単一のアイデンティティプロバイダーに常に依存することなく、分散型またはピアツーピア方式で提示および検証できます。これは、トークンの作成と検証のために中央のOpenIDプロバイダー(OP)に依存することが一般的なOIDCとは対照的です。
VCの主な利点は、プライバシー強化の可能性です。すべての属性を公開したり、単一のアイデンティティプロバイダーに依存したりするのではなく、ユーザーとAIエージェントは、特定のインタラクションに厳密に必要なクレームのサブセットのみを共有できます。この「選択的公開」機能により、特にインタラクションが複数のドメインや組織にまたがる場合、OIDCベースのアーキテクチャに固有の統合ロギングやクロスプラットフォーム相関に関する懸念を軽減できます。
しかしながら、OIDCを完全にVCベースのモデルに置き換えると、トレードオフが伴います。OIDCには既にトークンの更新、失効、およびオーディエンスの制限などの問題に対して充分にテストされたサポートを提供するライブラリとデプロイメントの堅牢なエコシステムがあります。VCは強力ですが、これらのフローを大規模に複製するには追加の作業が必要で、特に、検証の呼び出しごとに新しい署名チェックやブロックチェーンまたは分散型台帳とのやり取りが必要な場合はそうです。多くのエンタープライズ環境では、ステークホルダーは完全に分散化されたアイデンティティ・インフラストラクチャを事前に採用するのではなく、既存のSSOまたは多要素認証フレームワークにVCを組み込むことを好むかもしれません。
実際には、ハイブリッドソリューションが最も実用的であることがしばしば証明されます。ユーザーまたはAIエージェントは、大量の属性や規制承認をエンコードしたVCを保存および管理しながら、OIDCトークンを活用して既存の認証または認可エンドポイントとの互換性を引き出すことができます。たとえば、エージェントIDトークンには、振る舞い、プロパティ、コンテキスト、および関係属性に関する詳細なメタデータを含むVCを埋め込むことができます。OIDCと統合しているサービスプロバイダーは、埋め込まれたVCを解析して信頼とコンテキストの追加レイヤーを作成する選択肢を保持しながら、使い慣れたトークンベースのハンドシェイクを取得できます。OID4VCなどの例はこれをサポートしています(Yasuda et al., 2022)。
4. AIエージェントのためのスコープおよびパーミッションの定義
認証された委任は本質的に堅牢なスコープ設定メカニズムと結びついており、ユーザーはパーミッションと指示を明確かつ曖昧さのない方法で指定できなければなりません。これは、AIエージェントが実行できる非常に大きなアクションスペースと直接的に矛盾します。
信頼性と整合に関する多くの作業は、AIエージェントが指示に正しく従うことを確実にすることに焦点を当てていますが、誤った指示、プロンプトインジェクション攻撃、およびセキュリティ監査可能性の低下などのリスクがあるため、純粋な自然言語プロンプトは、スコープ、許可、およびセキュリティツールとしては不完全です。このセクションでは、柔軟な自然言語によるスコープ指示をヒューマン・イン・ザ・ループの設定で活用できる機械可読、バージョン管理可能、そして監査可能な構造化パーミッション言語に変換することを提案し、AIエージェントインフラストラクチャが自然言語による指示と堅牢で具体的なアクセス制御メカニズムの間のギャップを橋渡しする方法について説明します。
我々は、タスクのスコープ設定とリソースのスコープ設定を区別します:
- タスクのスコープ設定には、エージェントがユーザーに代わって実行することを認可されているアクションまたはワークフローの指定が含まれます。これらのアクションは、大まかなタスク(例:「財務レポートの下書きする」)からより詳細なアクション(例:「新しいデータベースエントリを作成する」)まで多岐にわたります;
- リソースのスコープ設定には、エージェントが使用または変更できるリソース(情報、API、ツールなど)を指定することが含まれます。
タスクのスコープ設定とリソースのスコープ設定は概念的には異なりますが、密接に関連しています。実行できるタスクを制限することは、(適切に設計された)エージェントが不必要なリソースにアクセスしないことも意味します;同様に、特定のリソースへのアクセスを制限すると、そもそも実行可能なタスクも制限されます。
このセクションでは、アクセス制御メカニズムを複雑なAIエージェントおよび自然言語ワークフローと統合する方法について説明します。構造化されたパーミッションの重要性、それがエージェントのスコープ設定に堅牢で一般化可能な基盤を提供する方法、自然言語と人間の監視がこれらのアクセス制御の柔軟なインターフェイスになる方法について説明します。
4.1 構造化されたパーミッション言語
スコープ設定メカニズムの大部分は、構造化された機械可読なポリシー仕様に依存しています。これらの仕様は、どのエンティティがどのような認可を持ち、どのような条件で、どのような権限を持つかを明確に定義します。パーミッションをエンコードするためのよく知られた言語やフレームワークはいくつか存在し、たとえば、XACML(eXtensible Access Control Markup Language)は、XMLを使用してアクセス制御ポリシーをエンコードおよび評価します(OASIS, 2013)、そしてデジタルコンテンツの利用許可を表現するために設計されたODRL(Open Digital Rights Language)(W3C, 2018)があります。その他の言語としては、OBAC(Brewster et al., 2020)、ROWLBAC(Finin et al., 2008)、KaOS(Van Lamsweerde, 2001)および Multi-OrBAC(Abou El Kalam & Deswarte, 2006)は、オントロジー(通常はOWLを使用して記述)に依存して、リソース、サブジェクト、および認可をモデル化します。Webベースのコンテキストでは、これはエージェントがアクセスできるURLとサブドメインをホワイトリストまたはブラックリストに登録するのと同じくらい簡単な場合がよくあります。
これらの構造化言語は機械可読であるため、従来の(AIではない)システムによって確実に適用できます。実用的な観点からは、リソースは通常は分離しており、分類、列挙、およびセキュリティドメインへのグループ化が可能なため、リソースのスコープ設定に適しています。たとえば、ポリシーが特定のディレクトリが特定のエージェントに対して読み取り専用であると宣言している場合、コンプライアンスの適用は簡単で、システムレベルで実装できます。
しかし、これらには3つの主な欠点があります。第一は、これらのフレームワークはリソースの列挙には適していますが、タスクのスコープ設定には柔軟性が低く、特にタスクがオープンエンドの場合や、一連の操作として簡単に説明できない場合にそうなります。第二に、ポリシー定義は、特に多数のリソースとタスクがある環境や、ウェブインタラクションの数が膨大になるWebコンテキストでは、長く複雑になる可能性があります。第三に、これらは多くの場合、環境に固有であり、エージェントがインタラクションするさまざまなデジタルシステムに合わせて更新する必要があります。
これらの欠点にもかかわらず、構造化パーミッション言語は、リソースのスコープ設定のための正確で簡単に監査できる基盤を提供するため、アクセス制御の基礎であり続けています。代替アプローチとして、スキーマ検証を使用してエージェントが環境とインタラクションする方法を制限する方法があります。これについては、サブセクションB.1で説明します。
4.2 認証フロー
エージェントの動作を制御するもう1つの側面は、認証フロー(つまり、エージェントがアクションを続行する前に、ユーザーまたは別の権限に確認を求めるタイミングを決定します)。すべてのアクセス決定を単一のポリシー定義にフロントロードするのではなく、認証フローは境界線または高リスクの操作に対してユーザーの承認を動的に要求できます。
このアプローチの主な利点は、ユーザーが静的ポリシーですべてのエッジケースを定義する必要がないことです。さらに、認証フローを他のスコープメカニズムと組み合わせることもできます:たとえば、ポリシーでは明示的に承認も禁止もされていないリソースには人間の承認が必要であると宣言できます。
一方、頻繁な認可プロンプトはユーザーエクスペリエンスに悪影響を及ぼし、「プロンプト疲労」(Baruwal Chhetri et al., 2024)につながる可能性があり、ユーザーは適切な確認をおこなわずに単純に権限を付与します。さらに、要求に明示的な認可が必要な場合の判断は簡単ではなく、誤分類によってプロンプトが過剰に表示されたり、重要な操作が気付かれずに見逃されたりする可能性があります。
実際には、適切に設計されたシステムでは、堅牢で構造化されたポリシー定義(一般的なシナリオ用)と、まれなアクションや特に機密性の高いアクション用の動的な認証フローを組み合わせることができます。このアプローチにより、ユーザーは日常的なチェックの大部分を自動化されたポリシーにオフロードしながら、新しいまたは曖昧なユーザー確認要求をエスカレーションする機能を維持できます。
4.3 自然言語メカニズム
ファインチューニングと並んで、プロンプトはモデルの行動を安全方向に導くためによく利用されています(Zheng et al., 2024)。このアプローチの合理的な拡張は、平易な言葉で記述されたパーミッションを解釈するようにLLMを訓練(またはプロンプト)することです。たとえば、ユーザーは「公開文書の要約を作成することは許可されていますが、機密メトリクスを公開してはいけません」と言うかもしれません。このような指示は、原理的にはLLMベースのシステムによって解析され、それに基づいて行動することができます。
このパラダイムの主な強みは、そのユーザーフレンドリーさです。技術に詳しくないユーザーにとっては、自然言語でポリシーを表現する方が、正式なルールを書くよりもはるかに簡単だと感じるかもしれません。さらに、自然言語は、構造化言語ではエンコードが難しい微妙な指示やコンテキスト依存の指示を捉えることができます。そのため、タスクとリソースの両方のスコープ設定に理想的です。最後に、自然言語は、他のLLMベースのエージェントとのやり取りなど、自然言語の読み取りや使用を必要とするアクションにポリシーを適用するために利用できます。
しかし、自然言語は、信頼性の高いポリシーの適用に必要な精度に欠けることがよくあります。たとえば、「機密データ」や「プライベートメール」などの用語は、コンテキストに応じて異なる解釈をされる可能性があります。この問題は、異なるポリシーが競合する場合に特に関係し、曖昧でコンテキストに依存する指示によって異なる解釈が生じる可能性があります。曖昧な自然言語の指示を解釈して適用するためにLLMだけに依存することは、セキュリティが重要なコンテキストではリスクを伴う可能性があります。
つまり、自然言語の指示は便利なメカニズムとして機能しますが(特に、他のメカニズムがあまり適していないタスクのスコープ設定の場合)、スタンドアロンのポリシーメカニズムとして使用するには信頼性が足りません。
4.4 構造化パーミッション、自然言語、およびユーザー監視の組み合わせ
基礎としてのリソーススコープ設定
最も広く適用可能な戦略は、構造化されたパーミッションを使用してリソースのスコープ設定を実施することであると主張します。自然言語メカニズムの脆弱性は、特にセキュリティやコンプライアンスが懸念される場合、AIエージェントのプロダクションレベルの使用には適していません。対照的に、構造化されたパーミッションは明確で決定論的であり、認可されていないアクセスに対する検証可能な保証を提供します。リソースのスコープ設定に焦点を当てると、すべての認可されたタスクを詳細に指定するオーバーヘッドも大幅に削減されます。エージェントは、ある程度、コンテキストのドメイン知識を使用して、タスクのスコープ設定の指示をリソースのスコープ設定の形式で表現しようとできます。リソースは一般に分離しており、ドメインに分類、列挙、グループ化できるため、リソースアクセスを制御すると、スコープ外のリソースを必要とする多くの潜在的なタスクが暗黙的に阻害されます。さらに、構造化されたリソーススコープ設定にはいくつかの利点があります。
- スクリプト、AIエージェント、または従来のワークフローなど、ユーザーがどのようにタスクを委任するかには依存しません;
- リソース(例:データベースやURLなど)に対する機械可読なパーミッションに焦点を置いた既存の非AIアクセス制御システムとの互換性が高くなります;
- 構造化されたロギングとバージョン管理に適しており、監査とコンプライアンスレポートを簡素化します。
ユーザーは自然言語で記述されたリソーススコープタスク制約を補足できますが、核となるリソースベースのポリシーは、言語の曖昧さやモデルの脆弱性の影響をほとんど受けないセーフティネットを提供します。LLMまたは別のAIエージェントが騙されたり、不整合が発生したりした場合でも、有害なアクションを実行する能力は基礎となるリソースパーミッションによって制限されます。
自然言語への接続
堅牢で監査可能である一方で、構造化されたリソーススコープ設定だけでは使いやすさと柔軟性に欠けます。これに対処するために、LLMへの指示(または別のスコープ設定プロンプト)で、適用すべきスコープ制限を柔軟に表現できます。これらの自然言語スコープは、対応する環境のエージェントまたはAIシステム(関連するリソースプロファイルに関するより詳細な知識を持つ)によって構造化されたスコープ設定形式に変換できます。自然言語と構造化されたパーミッション間の変換の例には、PostgreSQLの制限を生成するSubramaniam & Krishnan(2024)、およびカスタムJSONポリシーを生成するために検索を利用するJayasundara et al.(2024)を含みます。
同様のプロセスは、エージェントがインタラクションするさまざまな環境やデジタルサービスに対しても実行でき、幅広いサービスやコンテキストにわたって柔軟なパーミッション指示セットを適用できるようになります(AIエージェントの幅広いアクション空間を考えると重要です)。
人間をループに組み込む
重要な最終ステップは、人間の委任者を介してこれらの構造化されたアクセス制御を検証することです。認可ワークフローは、ユーザーがさまざまなシステムに対する構造化されたアクセス制御の制限を簡単にレビューして承認する機会を提供します。たとえば、Wright(2024)によれば、LLMエージェントは構造化された情報(この場合は会議の日程)について合意し、その後、人間のユーザーによって確認されます。
ハイブリッド実装として組み合わせ
これらの要素を実装に組み込むのは比較的簡単です。LLMは、高レベルの自然言語リソース制約を、ユーザーが後でレビューして承認できる規則正しく構造化されたルールに変換するのに役立ちます。例えば:
- ユーザーは次のように書いています:「エージェントに『projectAlpha』に関するディレクトリの読み取りと書き込みを許可しますが、財務フォルダーを含むフォルダーへのアクセスは許可しません;」
- LLMは、この要件を、ユニバーサルパーミッション言語(例えば、XACML)またはリソースで使用されている特定のパーミッション言語(例えば、データベースのSQLアクセスポリシー)のいずれかでポリシー定義に変換します。このような特定のケースでは、LLMは「projectAlpha」リソースを列挙しながら、「financials2023」へのアクセスを明示的に拒否します;
- ユーザーはポリシーをレビューし、必要に応じて修正し、最終決定します。
このようなワークフローの多くの具体的な詳細、例えば中間検証チェックや構造化言語へのLLMによる変換の堅牢性の評価などに対処する必要がありますが、これらの詳細は将来の作業として残します。
最終的に、構造化された明確なリソース制約に焦点を当てることが、特定の環境でAIエージェントが認可された境界内にとどまるようにするための最も信頼性の高い方法です。より高レベルの(多くの場合、自然言語による)タスク制約の余地はまだありますが、これらを主要な強制メカニズムへのガイダンスとして扱う必要があります。実際、自然言語はエージェントアクションの非常に大きな可能性に適切に対処できますが、アクセス制御への変換により、エージェントアクションの制限が有限の監査可能な制御に根ざします。構造化されたリソーススコープ設定により、モデルの調整だけへの依存が軽減され、敵対的なプロンプトインジェクション攻撃のリスクが軽減され、確立されたセキュリティメカニズムとの統合が簡素化されます。このアプローチを適切に設計された認証フローと組み合わせ、生成されたポリシーをユーザーが解釈できるようにすることで、人的エラーの可能性が減り、説明責任が強化され、認証された委任の堅牢性が向上します。
4.4.1 エージェント間のスコープ設定
このアプローチは、ユーザーエージェントサービスモデルを超えて、エージェントが自分の代わりにアクションを実行する他のエージェントにその制限を伝播するマルチエージェント設定に適用できます。ユーザーがエージェントAliceの認可を指定したとします。タスクを実行するために、Aliceが別のエージェントBobと自然言語でインタラクトするとき、BobはAliceのスコープ設定指示を解析し、自分の環境で解釈できます。そうすることで、Bobは割り当てられた操作が元のスコープ内にとどまっていることを確認し、実行されたアクションとアクセスされたリソースの監査可能な受領書を提供できます。これは、エージェント間の通信が異なる組織にまたがり、それぞれに異なるポリシーとリソース制約があるシナリオで特に役立ちます。
具体的な例として、Aliceがプロジェクト管理エージェントで、Bobが会計エージェントであるとします。ユーザーはAliceに財務データの要求を平易な英語で説明します;Aliceは転送された要求と認可の説明をBobに送信します。Bobは認可の構造化された解釈(例えば「『transactions2025』データセット、列:合計金額、ベンダー名、への読み取り専用アクセス」)を返信し、これがログに記録されてユーザーまたはAliceによって承認されます。
このようなワークフローにより、エージェントが柔軟な自然言語で通信する場合でも、その基礎となるスコープ設定と記録保持は、監査可能な決定論的ポリシーに固定されたままになります。その結果、認可されていないデータ共有や無制限なエージェント動作のリスクが大幅に軽減され、各エージェントが委任者から制限された資格情報を「継承」する能力が厳密に制御されます。
5. Discussion
5.1 OpenID Connectアプローチの問題点
ここで提案しているOpenID Connect(OIDC)およびOAuth 2.0ベースのフレームワークは、認可と委任のための堅牢で実証済みのメカニズムを提供しますが、トレードオフが伴い、さらに、プライバシー、セキュリティ、監査可能性の点で異なるトレードオフを伴う代替手段よりも複雑になる可能性があります。
複数のサインインフローによるオーバーヘッド
OpenID Connectアプローチの大きな欠点は、個々のサービスプロバイダー間でAIエージェントを認可するために必要な複数のサインインフローによって生じる潜在的なオーバーヘッドです。これは、新しいEメールクライアントを設定するときのエクスペリエンスに似ており、ユーザーがさまざまなサービスへのアクセスを認可するために繰り返しログインする必要があります。このような認可フローは、各プロバイダーがAIエージェントの委任資格情報を個別に検証することを保証することでセキュリティを強化しますが、安全なシステムへのアクセスを遅くすることでユーザビリティを犠牲にします。理論上は、完全なOIDC認証フローを実行せずに委任トークンを直接提示することでこの負担を回避することができます;しかし、このショートカットでは、トークンの鮮度と検証に関連する重要なセキュリティ保証が犠牲になります。
OpenIDプロバイダーへの依存度とプライバシーのリスクが高くなる
OpenIDプロバイダー(Google、Facebook、または同等の組織など)への依存は、体系的なプライバシーの懸念をもたらします。OIDCプロバイダーはすべての認証フローを仲介するため、さまざまなサービス間で個々のAIエージェントのインタラクションを追跡して相関させることができます。これには、統計的な利用分析の収集や、広範な行動プロファイリングを容易にするリライングパーティーに対するログ共有の要求が含まれます。このような中央集権化された可視性は、ユーザーのプライバシーを侵害し、潜在的な単一監視ポイントを作り出します。これらのリスクに対処するには、ペアワイズ仮名識別子やログ共有要件の最小化などの強力なプライバシー緩和策が必要ですが、これらのメカニズムはシステムにさらなる複雑さを追加します。
W3C検証可能なクレデンシャルと比較したときの複雑さ
この論文では、OIDCフレームワーク内にW3C検証可能なクレデンシャル(VC)を埋め込む機能を強調していますが、完全なOIDC認可フローは、ネイティブのW3C VCベースの委任および認証プロセスと比較すると、依然として不必要に重労働である可能性があります。W3C VC発行、認証、および委任メカニズムは、繰り返しおこなう認可フローと中央集権プロバイダーの仲介による追加のオーバーヘッドを被ることなく、AIエージェントのアイデンティティ検証に関する同じ要件を直接満たすことができます。さらに、W3C VCベースのアプローチは、トラストを仲介したり認証情報の利用を追跡したりする単一のプロバイダーに依存しないため、本質的にプライバシー保護が優れています。合理化されたVCベースのプロセスは、必要に応じてOIDC互換のクレデンシャルを生成し、シンプルさとプライバシーを維持しながら相互運用性を実現できます。同様に、OAuth 2.0仕様に代わる他の提案された代替案は、Grant Negotiation and Authorization Protocol(GNAP(Richer & Imbault, 2024)です。これらの代替アプローチをさらに調査することは、AIエージェント委任のための軽量なソリューションとしての実現可能性を判断するために不可欠です。
よって、これらの制限はOIDCベースのフレームワークにおけるセキュリティ、ユーザービリティ、およびプライバシーの間の重要なトレードオフを強調します。提案しているアプローチは段階的かつ相互運用可能な前進であることは変わりありませんが、これらの課題に対処することはAIエージェントの認証と委任のための堅牢で実用的なシステムを確保する上で重要になります。
5.2 自然言語によるスコープ設定の限界
自然言語によるスコープ指定指示を構造化されたパーミッション言語に変換することは、より柔軟なインターフェースを可能にしますが、いくつかの重要な課題も生じさせます。
信頼性と正確性の評価
最も困難なことの1つは、ユーザーによる自然言語仕様から機械可読なポリシーへの翻訳が正確であると保証することです。自然言語の指示には、コンテキスト依存またはあいまいな用語が含まれることが多く、本質的にAIシステムによる誤解が生じやすいです。ヒューマン・イン・ザ・ループなアプローチでは、ポリシーのレビューを通じてこれらのリスクを軽減できますが、このような人間による検証は絶対に確実ではありません;ユーザーは、微妙な翻訳エラーをうっかり見逃してしまう可能性があります。さらに、パーミッションの仕様の複雑さが増すにつれて、元の自然言語の指示と生成された構造化ポリシー間の整合性を検証することが、技術的(ポリシー定義が巨大なため)にも認知的にも(人間のレビュー担当者の負担のため)難しくなります。
LLM攻撃の新たな脅威ベクトル
言語ベースのインターフェースの弱点を悪用すると、純粋な静的アクセス制御では存在しない新たな脅威が露呈する可能性があります。プロンプトインジェクション攻撃やジェイルブレイク攻撃により、大規模な言語モデルが強制的に元のユーザーの意図を超えるポリシーを生成または受け入れるようになり、認可されていない権限が取得される可能性があります。リソースまたはタスクのスコープ指定の指示を通常のチャットセッションやインタラクションから分離すると、攻撃の可能性は減りますが、それでも防御が必要な新しい差別化された攻撃対象領域が存在することになります。
文脈からの逸脱
時間の経過とともにポリシーが進化したり、タスクのコンテキストが変化したりすると、以前の自然言語の指示が古くなったり、新しく導入されたリソースと一致しなくなったりするリスクがあります。指示の複数の改訂にわたって一貫性を維持することは簡単ではありません。
制限の強制が第三者に部分的に依存する
いくつかの状況によっては、アクセス制御ルールはインタラクションする外部環境またはエージェントに適用されます。これらのアクセス制御の適用に対するセキュリティを維持するには、ネイティブエージェントがルールに従うことを信頼するだけでなく、対応する当事者がルールを強制することが必要な可能性があります。このような場合、第三者の信頼性が重大な障害点になります。
5.3 モデルベンダーがそれを提供できるか?
モデルベンダー(例えば、OpenAI、Anthropic、Google)は、AIシステムがデジタルサービスにアクセスする際にどのユーザーが代表されるか、および意図されたスコープやパーミッションは何かを共有するためのツールを提供できます。これは推奨されます。しかし、AIシステムのユーザーエージェント文字列に情報を含めたり、AIシステムによって実行されるAPI呼び出しに情報を書き込んだりするなど、このような情報を共有する現在のアプローチは、セキュリティと検証可能性の観点から不十分です。代わりに、これらのサービスは、ユーザーエクスペリエンスを変更することなくAIシステムのOpenIDプロバイダーとして機能する(またはOpenIDプロバイダーと提携する)ことができます。または、認証された委任フレームワークの別のインスタンス化を希望する場合は、AIエージェントとユーザーのための堅牢で一意なIDと組み合わせたW3C 検証可能なクレデンシャルを提供することができます。
認証された委任の実装は、AIシステムとエージェントがセルフホストされている場合やカスタムインフラストラクチャ上にデプロイされている場合にも実現可能です。これには、人間のユーザー向けの内部アイデンティティ管理インフラストラクチャの活用や、カスタムパーミッション制御の組み込みが含まれます。このようなシステムは組織内で内部的に運用でき、AIシステムの使用がさまざまなテクノロジースタックとモダリティにわたるアイデンティティおよびアクセス管理(IAM)ポリシーと委任フレームワークと調和するようにできます。
5.4 robots.txtとインタラクトする方法
Robots.txtは、法的拘束力はないものの、数十年にわたって現代のWebを支えてきました。Robots.txtは、ユーザーエージェントにサブルートのルールを与えるという単純な一連の指示に依存しています。最近のスクレイピングの急増により、Longpreら(2024)の新しいユーザーエージェントルールが急速に採用されるようになったのと同じように、適切なインセンティブがあれば新しい指令をWeb全体に簡単にデプロイできます。
このシステムは、AIエージェントが多数存在するWebにもまだ存在しています。Webサイトはスクレイピングをブロックしたいと考えるかもしれませんが、エージェントを正しいサブルートに誘導して、クレデンシャルを共有し、インタラクトできるようにしたいと考えるかもしれません。たとえば、Webサイトはスクレイピングをブロックし、人間のユーザーがインタラクトできるようにし、AIシステム向けに設計されたAPI自然言語インターフェースにAIエージェントを直接送信したいと考えるかもしれません。
資格情報を共有してインタラクトできる正しいサブルートにエージェントを誘導するため、新しいユーザーエージェントAgentBotを定義し、それを特定のインタラクトルート(例:/AgentInterface/)に強制に送ることができます。robots.txtはルールではなくガイドであるため、このルートはアクセスできるサービスや存在するサイトマップに関するより詳細な情報を提供することができます。このようなrobots.txtは、エージェントへの最初のガイドとしてのみ必要です。
5.5 認証された委任のための法的な根拠
代理権法は、一方の当事者である本人が、別の当事者である(人間の)代理人に代理行為を委任する状況を扱っています(Garner, 2019)。本質的に、代理権法は、代理人の行為に対して委任者がいつ責任を負うかを定め、最終責任を負うのが誰であるかを確かめなければならないことで第三者が不当に不利益を被らないようにするものです。
代理権法の主な成果は、市場取引に信頼と自信を植え付けることです:責任と権限に関する明確なルールを提供することで、代理権法は不確実性を減らし、より効率的な市場運営に貢献します(Posner, 2019; Williamson, 1975; Casadesus-Masanell & Spulber, 2005)。
代理権法における中心的な概念の一つは「表見的権限」であり、代理権の再定義(三度目)において広く議論s慣れています(American Law Institute, 2006)。この原則では、たとえ本人が明示的に権限を与えていなかったとしても、合理的な第三者が代理人が実行を認可されていると認識した行為については、本人が責任を問われる可能性があります。この原則は市場の安定性の維持にも役立ちます:代理人が本人に代わって合理的な方法で行動しているように見える限り、第三者は取引を進める前に代理人の資格情報のあらゆる側面を調査したり、権限の主張を一つ一つ検証したりする必要はありません。
既存の代理人に関する原則が、学習、自己修正、自律的に動作できるAIエージェントにどのように適応するかは不明です(Balkin, 2015; Adler et al., 2024)。意図、同意、および監視可能な権限という従来の概念は、現在の自律システムに適用することは困難です。これらの不確実性に対応するために、認証された委任フレームワークは、各権限委任が検証可能なモデルを提供します。このフレームワークでは、外見に頼るのではなく、第三者がAIエージェントが実際に本人に代わって行動することを認可されていることを自動的に確認できます。そうすることで、見かけの権限の原則に頼る必要性が減り、アクションの誤帰属のリスクが軽減されます。
Air Canadaをめぐる最近の論争は、これらの原則が実際にどのように役割を果たすかを示しています(Civil Resolution Tribunal (2024), British Columbia)。この事例では、航空会社は、オンラインチャットボットによって提供された情報については責任を負わないと主張しました。これは暗黙的に、チャットボットを航空会社とは別の独立した存在のように扱うことを示唆しています。しかし、裁判官の見解では、チャットボットはAir Canadaのデジタルインフラの一部として存在しており、そのため会社は提供された情報に対して責任があります。従来の法律と衡平法の原則によれば、チャットボットの出力は、たとえ自律的に生成されたものであっても、航空会社が一般に公開する情報の一部を構成します。航空会社の責任回避の試みは、人間であれ機械であれ、企業が作成した表記に責任を負わなければならないという原則に反します。この事例は、企業が自社のAIエージェントの行動に対して責任を負う可能性があることを強調しており、これは多くの学者も支持している見解です(Adler et al., 2024)。より広い視点から見ると、この事例は、AIを介したインタラクションにおける責任と権限を明確にし、最終的に消費者の信頼と市場の安定性を守ることができる、認証された委任フレームワークのような堅牢な技術的および法的メカニズムの必要性が高まっていることも浮き彫りにしています。
代理権法以外にも、統一電子取引法(UETA)のような電子取引に関する既存の法的枠組みが、ある程度の指針を提供しています。UETAは、電子通信と自動化プロセスが契約の締結と履行において重要な役割を果たすことを認識し、電子商取引の現実に対応するために米国の49州で採択された統一法です(Greenwood, 2024; National Conference of Commissioners on Uniform State Laws)。UETAでは、当事者は合意されたセキュリティ手順とエラー検出プロトコルを採用して、電子記録が意図された合意を真に反映していることを保証することが推奨されています。一方の当事者がこれらの手順に従わず、検出されるはずのエラーが気付かなかった場合、もう一方の当事者はそのエラーの結果を回避することが許可される場合があります。同様に、個人が電子エージェントとのインタラクション中にエラーを犯し、システムが合理的な修正メカニズムを提供しない場合、UETAは定義された条件下でその個人に救済措置を与えることを想定しています。
これらの規定は、デジタル商取引における信頼には、電子契約に拘束される意思があるだけでは不十分であるという認識を反映しています;また、権限を検証し、間違いを修正し、自動化されたプロセスがプリンシパルの意図した指示を忠実に実行することを保証する信頼性の高い方法も必要です。認証された委任フレームワークは、これらの目標とよく一致しています。検証可能な権限チェーンをAIエージェントとのインタラクションに統合することで、合意されたセキュリティ手順のデジタル版を提供します。そうすることで、AI駆動型プロセスがその権限のスコープ内で動作していたかどうかに関する誤解や論争を減らすことができます。
AI強化システムにおけるトラストと説明責任の重要な要素は、意味のある人間の監視を維持することであり、これはしばしば「ヒューマン・イン・ザ・ループ」要件と呼ばれます。たとえば、EU AI法は、倫理的で透明性があり説明責任のある結果を保証するために、リスクの高いAIの決定に人間の関与を維持することの重要性を強調しています(European Commission, 2021)。認証された委任フレームワークは、エージェントワークフローにおける人間の役割を明示的にすることで、この原則をサポートします。不透明なコード層の背後にあるAIシステムに権限を委任するのではなく、第三者はAIがいつ、どのように、どのような条件で行動することを認可されているかを明確に確立できます。これにより、人間が介入して決定を検証し、エラーを修正し、自動化されたアクションが包括的な法的および倫理的基準に準拠していることを確認できます。
AI駆動型エージェントの文脈における技術と法律の相互作用は複雑で進化しています。法的基盤を強化し、認証された委任のフレームワークを採用し、重要な局面では人間の監視を統合することは、新興のAIシステムが市場の効率性を高めるだけでなく、トラスト、公平性、説明責任という中核的な価値を維持できるようにするためのステップです。人ヒューマン・イン・ザ・ループ・メカニズムの実際の実装を調査する研究(Mosqueira-Rey et al., 2023)を参考にして、さらなる実証的および教義的な分析により、この議論を深めることができるでしょう。
6. Conclusion
この論文では、AIエージェントへの認証された委任のための実用的なフレームワークを提示し、デジタル空間における認可、説明責任、アイデンティティ検証、およびアクセス制御管理に関する緊急の課題に対処します。既存の OAuth 2.0およびOpenID ConnectプロトコルをAI固有の資格情報と委任メカニズムで拡張することにより、私たちのアプローチは、明確な説明責任チェーンを維持しながら、ユーザーからAIエージェントへの権限の安全な委任を可能にします。提唱したトークンベースのフレームワーク(ユーザーIDトークン、エージェントIDトークン、および委任トークンで構成する)は、エージェントアイデンティティの検証、パーミッションの制御、監査証跡の維持のための堅牢な基盤を提供し、自然言語の指示に応じて生成されるきめ細かく堅牢なスコープ制限をサポートします。私たちの主な貢献は、確立されたインターネット規模の認証(例えばOpenID ConnectやW3C VC)とアクセス管理プロトコル(例えば、XACML)を、自動ネゴシエーションやWebサービスインタラクションなどの分野での実際のユースケースで示すように、現在のシステムとの互換性を維持しながら、AIエージェント委任の固有の課題に対処するためにどのように適応できるかを示したことです。AIエージェントがデジタル空間で普及するにつれて、このようなフレームワークは、エージェントが人間のプリンシパルに対して責任を持ちながら適切な範囲内で動作することを保証する上で不可欠になります。今後、主要な研究の方向性としては、一般的なAIエージェントタスクの標準化されたスコープ定義の探索、プライバシーを保護する委任メカニズムの検討、サービスプロバイダーがエージェント認証ポリシーを実装および管理するのに役立つツールの作成などが挙げられ、最終的にはAIシステムを既存のデジタルインフラストラクチャに安全かつ生産的に統合できるようにすることを目指します。
Appendix A 技術詳細
A.1 エージェント相互認証のためのフェデレーションされたOpenIDプロバイダー
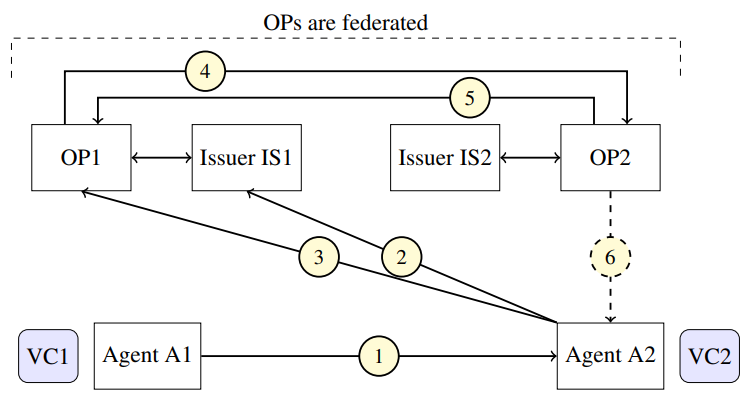
AIエージェントの主な目標の1つは、エージェントが既存のWebサービスや他のAIエージェント(AIエージェント)とインタラクションできるようにすることです。セキュアなインタラクションを可能にするには、AIエージェントは相互認証をおこない、エージェントIDトークンと委任トークン含むクレデンシャルを互いに検証する必要があります。図4は、フェデレーション環境におけるこの認証プロセスを示しています。
認証フローは、エージェントA1が検証可能なクレデンシャルをエージェントA2に提示したときに始まります。VCには、ユーザーのIDトークンとエージェントIDトークンを含む、それぞれのOpenIDプロバイダーを通じて検証する必要があるクレームが含まれています。OP1のAPIは保護されているため、A2はホームドメインでOP2によって以前に発行された独自のエージェントIDトークンを使用して自身を認証する必要があります。このクロスドメイン検証はフェデレーションによって実現され、OP1はOP2と通信してA2のクレデンシャルを検証します。この図はA1の観点からの認証を示していますが、プロセスは相互的であり、両方のエージェントがそれぞれのOpenIDプロバイダーを通じて互いの委任された権限とクレデンシャルを検証できることを保証します。
A.2 AIシステムとAIエージェントの身元確認
AI技術の導入が直面する課題の1つは、AIエージェントを含むAIシステムのインスタンスの識別メカニズムを確立する必要があることです(Chan et al., 2024b)。ここでは、2つの基本的な識別子の種類を区別すると便利です:
- ローカル識別子:ローカル識別子は、特定のドメイン内のAIシステムのインスタンスを他のインスタンスと区別するために使用できる一意の文字列(例えばUUIDv2)です。つまり、ドメイン内の他のシステムやエンティティは、そのローカル識別子を使用して各AIシステムを特定できます。ローカル識別子はドメイン外では意味をなさない可能性があるため、グローバル識別子へのマッピングが必要です。
- グローバル識別子:グローバル識別子は、AIシステムをインターネット上のどこからでも参照(もしくは照会)できるようにします。これにより、エージェントはさまざまな地域にある他のAIシステムや他のAIエージェントとインタラクションできるようになります。 スケーラビリティの観点からは、AIエージェントのグローバル識別子からローカル識別子にマッピングし、そのホームドメイン内の他のシステムがそのAIエージェントをサポートできるようにすること、たとえばそのホームドメイン内のOPによるローカル認証によって、ドメイン内のエージェントが真に存在していることが証明されること、は有用です。 AIシステムまたはエージェントに属するグローバル識別子は、分散型識別子(DID)構造(W3C, 2021)により、DIDに基づいて機能するDLTベースのサービスとの便利なインタラクションが可能になります。
今日、OAuth 2.0とOIDCの導入が普及しているため、これらの導入で既に使用されている既存の識別子構造の一部を再利用することは有用です。AIエージェントをOAuth 2.0におけるクライアント(ネイティブまたはホストされたサービス)と見なすと、OAuth 2.0クライアントが認可サーバー(またはOP)とインタラクションするために利用する2つの重要なパラメーターを再利用できます。これらのパラメーターはclient_idとclient_secretです((Hardt, 2012)のセクション2.3.1を参照)。OAuth 2.0のクライアントIDとクライアントシークレットパラメーターは、認可サーバー(OP)が特定のクライアント登録プロトコルを使用して事前にOPに登録されたクライアントを認識するために利用されます(Jones et al., 2015)。AIシステムとAIエージェントを識別するという現在のコンテキストでは、クライアントIDは特定のOPによってサービス提供されるドメイン(つまり、クライアントが登録されているドメイン)だけで意味を持つローカル識別子と見なすことができます。しかし、クライアントIDは委任トークン内のアクションスコープによって定義された特定のタスクを実行するためにユーザーがAIエージェントへの委任を認可していることを示す委任トークンをOPが発行するための基礎となる可能性があります。
A.3 IDトークンの脅威モデル
私たちの提案は、発行されたトークンの信頼性から委任の性質に至るまで、さまざまなセキュリティ上の脅威に対してセキュアであることを目的としています。
IDトークンに関しては、Chanら(2024b)は、AI IDシステムが防御しなければならない3つの基本的な脅威を特定しています。第一の脅威は改竄であり、IDが作成者と受信側の間で転送されている間に攻撃者がIDを変更し、重要なシステム情報や属性を変更する可能性があります。第二の脅威はIDスプーフィングであり、攻撃者が不正なIDを作成し、それが正当な作成者(大手AI企業など)からのものであると偽って主張し、悪意のあるシステムが信頼できるシステムを装うことがあります。第三の脅威はインスタンススプーフィングであり、攻撃者が正当なIDを取得し、それを自分の認可されていないAIインスタンスで使用しようとして、元のシステムに関連付けられた評価や権限を本質的にはハイジャックします。これらの脅威に対抗するために、著者らは、WebサイトでのHTTPS証明書の動作と同様に、ID自体とシステムの出力の両方をカバーするデジタル署名をIDに実装することを著者たちは提案しています。しかし、彼らは重要な制限を指摘しています:署名はIDと出力の両方をカバーする必要があるため、出力を変更すると(それが無害なものでも)IDが無効になり、セキュリティとユーザービリティの間で難しいトレードオフが生じます。堅牢なAIシステム識別に対するこれらの脅威は、AIエージェントにとっての認証された委任のタスクにも当然広がり、AIシステムの検証、人間の委任の検証、および有効な委任の検証のすべてに堅牢性が求められます。
OpenID Connectは、これらの堅牢なID以外にも、複数のさらなる脅威を防ぐために役立ちます。組み込みメカニズムにより、OIDCはペアワイズ仮名識別子を使用してAIインスタンスがさまざまなサービスで異なるものとして見えるようにし、アイデンティティ相関攻撃を防ぎ、プラットフォーム間でインスタンスの動作を追跡する試みを阻止できます。セッション管理機能により、アクティブなAIインスタンスに対するセッションハイジャックの試みを防ぐことができ、動的クライアント登録により認可されていないエンドポイントによるなりすましを防ぐことができます。最も重要なのは、OIDCのスコープ設定とオーディエンス制限メカニズムにより、認可スコープの乱用やインスタンス間の権限昇格を防ぐことができ、AIインスタンスが意図したパーミッションを超えたり、他のインスタンス用のトークンを使用したりすることを防げることです。このプロトコルの検出メカニズムにより、アイデンティティプロバイダースプーフィングも防止できるため、IDエコシステムにもう1つのセキュリティレイヤーが追加されます。
Appendix B アクセス制御管理における代替手段
B.1 スコープ設定としてのスキーマ検証
構造化パーミッション言語の代替アプローチとして、スキーマ検証を利用してエージェントが環境とインタラクトする方法を制限する方式があります。このアプローチでは、AIエージェントのありうる出力またはクエリは、事前に定義されたスキーマに準拠している必要があります(Allemang & Sequeda, 2024)。たとえば、エージェントがRDFタプルを使用してのみ通信できる場合、システムはエージェントが生成できる許容クラス、プロパティ、または関係に関するルールを適用できます。
実際には、スキーマ検証は、システムが標準化されたデータ形式(JSON、XML、RDFなど)に基づいて設計されているシナリオで特に強力になります。エージェントをこれらの形式に制限し、すべての出力を検証することで(たとえば、JSONスキーマ(ECMA, 2017)またはSHACL(W3C, 2017))を利用し、スキーマ検証はどのアクションが実行可能であるかを間接的に制御します。たとえば、エージェントが特定の述語(例、「hasTitle」や「hasSummary」)と特定のクラス(例、「Document」)を持つRDFトリプルの生成のみを許可されている場合、そのスキーマドメインの外部のデータを任意に変更することはできません。
構造化パーミッション言語と同様に、非AIシステムでは、エージェントの出力が特定のスキーマに準拠しているかどうかを迅速かつ確定的に検証できます。さらに、エージェントの出力はすでに構造化されているため、非構造化テキストの解析に比べてスキーマ検証が簡単な場合があります。標準出力では、すべてのアクションを構造化クエリでキャプチャして監査できるため、ログ記録も簡素化されます。
一方、厳格なスキーマは、特にタスクのスコープ設定のコンテキストで柔軟性を低下させる可能性があります。微妙なニュアンスや創造的な出力を必要とするタスクは、大幅な複雑さを伴わずにスキーマベースのアプローチではキャプチャすることが難しい場合があります(特に、そのようなタスクが時間の経過とともに進化する場合)。さらに、表現力と安全性の両方を兼ね備えた堅牢なスキーマを設計するにはかなりの労力が必要であり、エージェントをそのスキーマ内でのみ動作するようにトレーニングまたはプロンプトで指示する必要があります。
それでも、スキーマ検証は、特に許容されるアクションの範囲を構造化された形式でコード化できる場合には、リソースのスコープ設定のための強力なメカニズムになります。
B.2 制御された自然言語
自然言語のパーミッションは柔軟ですが、具体性に欠けます。制御された自然言語(CNL)(つまり、文法と語彙が制限された自然言語のサブセット)は、構造化された仕様と自由形式の仕様の中間に位置する興味深いものです。自然言語の読みやすさをある程度維持しながら、自動解析や形式検証に適しています。CNLインターフェースを使用するエージェントは、リクエストを曖昧さなく解釈できる可能性があり、これにより、誤って解釈するリスクが軽減されます。しかし、セキュアで表現力豊かなCNLを設計することは難しい場合があります:自由度が高すぎると、曖昧さが増し、LLMがインジェクション攻撃にさらされる危険性がありますが(Perez & Ribeiro, 2022)、制限が厳しすぎるCNLは構造化言語と同じ問題に悩まされることになります。
Appendix C ユースケース例
このセクションでは、認証された委任によってAIエージェントのやり取りが安全かつ説明責任が確保される 4 つのシナリオについて説明します。各例では、委任資格情報の構造、委任資格情報が適用するスコープ設定メカニズム、および説明責任の維持における役割について説明します。
C.1 WebブラウザをおこなうAIエージェント
シナリオ
ユーザーはAIエージェントを使用し、予定のスケジュール設定、情報の取得、オンライン支払いの管理などのタスクを実行します。エージェントのアクセスは特定のWebサイトに制限され、取引金額など、エージェントが実行できるアクションに明確な制限が設けられる必要があります。
アプローチ
- 委任クレデンシャル:クレデンシャルでは以下を指定します:
- ユーザーアイデンティティ:委任ユーザーの一意の識別子
- エージェントアイデンティティ:エージェントの機能(例:ブラウザベースのインタラクション)を含む、エージェントの一意の識別子
- スコープ:承認されたウェブサイト、許可されたアクション(例:スケジュールの閲覧、支払いの実行)、および特定の成約(例:支払限度額、有効期間)のような制限
- アクセスでの強制事項:Webサイトは、ログインまたはトランザクション試行時にエージェントのクレデンシャルを検証します。承認されていないサイトや事前に定義された制限を超えるような人kされていないアクションは自動的にブロックされます。
- 監査可能性:エージェントの一意の識別子に関連付けられたログにはすべてのトランザクションとアクションが記録され、インタラクション後のレビューと追跡が可能になります。
重要である理由
構造化されたクレデンシャルにより、エージェントが認可されていないウェブサイトにアクセスしたり、意図しないアクションを実行したりすることができないことを保証します。これにより、機密性の高いユーザーデータが保護され、ユーザーがオンラインインタラクションを制御できるようになります。
C.2 APIだけのデータ管理者
シナリオ
組織はAIエージェントを使用し、運用や在庫に関する情報を提供する内部APIからのデータを集約および分析をおこないます。エージェントのアクセスは特定のAPIに制限され、データのクエリなどの非破壊的なアクションに限定される必要があります。
アプローチ
- 委任クレデンシャル
- ユーザーアイデンティティ:委任元の組織または個人の認証された識別子
- エージェントアイデンティティ:エージェントの目的(例:データ集約)を指定する、エージェントの一意の識別子
- スコープ:アクション(例:読み取り専用アクセス)および操作上の制約(例:レート制限や有効期限)を持ち、特定のAPIを規制されたアクセス権限
- APIでの強制事項:APIはクレデンシャルを検証し、データの書き込みやでのデ付与されたパーミッション外のアクションを拒否します。
- クレデンシャル管理:委任トークンは、古いクレデンシャルに関連したリスクを軽減するために定期的にローテートまたは更新されます。
重要である理由
エージェントのスコープが制限されているため、意図せずに機密データを変更したりアクセスしたりすることはできません。詳細なアクセスログにより説明責任が確保され、異常な動作に迅速に対応できます。
C.3 SSHを介するリモート仮想環境
シナリオ
ユーザーは、シミュレーション実行やデータ処理など、リモート仮想環境でのタスクを実行するようにAIエージェントに指示します。エージェントのアクセスは、特定のコマンドとディレクトリに制限する必要があります。
アプローチ
- 委任クレデンシャル
- ユーザーアイデンティティ:仮想環境プロバイダーによるユーザーの認証された識別子
- エージェントアイデンティティ:ロール(例:シミュレーション実行)を特定するエージェントに紐づけられたクレデンシャル
- スコープ:特定のディレクトリにアクセスし、定義されたコマンドを実行し、制限された時間枠内でアクションを実行するパーミッション
- 環境での強制事項:サーバーはアクセスポリシーを強制します。設定ファイルの変更や機密ディレクトリへのアクセスのような、認可されていないアクションは拒否されます。
- 監査証跡:タスク後のレビューのため、環境はエージェントによって実行された各コマンドをその一意の委任クレデンシャルと紐づけてログに記録します。
重要である理由
制限された委任クレデンシャルは、エージェントがアサインされたスコープ内だけで操作をおこない、意図していないまたは悪意のあるアクションから環境を保護することを保証します。
C.4 エージェント間の協力
シナリオ
2つのAIエージェントが、イベントの計画や契約交渉などの複雑なタスクで協力します。各エージェントには、一方が物流を担当し、他方が財務を管理するなど、尊重する必要がある個別のロールとパーミッションがあります。
アプローチ
- 委任クレデンシャル
- ユーザーアイデンティティ:委任元の組織または個人の認証された識別子
- エージェントアイデンティティ:各エージェントはそのロールと能力を説明する一意のクレデンシャルを受け取ります。
- スコープ:
- エージェント1:サービスの予約やスケジュール設定のような物流タスクのためのパーミッション
- エージェント2:明示的な予算制約をともなう支払いの実行のような財務タスクのためのパーミッション - エージェント間の検証:各エージェントはリクエストを他のエージェントに発行するとき、そのクレデンシャルを含めます。受信したエージェントは実行する前にスコープ内のリクエストであることを検証します。
- 協力メカニズム:エージェントは自然言語を使って通信しますが、実行可能なすべてのリクエストは検証のためにクレデンシャルを参照します。
- 監査可能性:クレデンシャルの参照を含むすべてのインタラクションのログにより、タスクと決定の明確な記録が確保されます。
重要である理由
エージェント間のインタラクションにスコープルールを組み込むことで、協力の安全性と説明責任が維持されます。各エージェントは事前に定義された制限内で動作し、意図しないアクションや誤ったコミュニケーションのリスクを軽減します。